In previous articles, we explored a high-level overview of two kinds of neural networksA neural network is an AI model inspired by the human brain's structure and function. It consists of layers of interconnected nodes (neurons) that can learn to perform tasks by adjusting the strength of these connections based on data.
See More...See Less..., supervised neural networksThese are neural networks trained on labeled data. They learn to predict outputs when given inputs, making them ideal for applications where the relationship between input and output is known.
See More...See Less... and unsupervised neural networksUnsupervised neural networks are designed to learn hidden patterns and structures from unlabeled data, typically used for clustering or associating different inputs.
See More...See Less.... Today, we'll peel back another layer of this digital cortex and explore how these networks evolve from their 'naive' initial state to a 'trained' state where they can make decisions, identify patterns, or generate new creations. We previously explained concepts using coins as an analogy. We’ll continue a little further with that theme.
Supervised or Unsupervised Learning? How to Train a Machine
In the world of machine learningMachine Learning is a subset of artificial intelligence (AI) focused on building systems that learn from data. It enables computers to improve their performance on a specific task with data, without being explicitly programmed. This involves algorithms that can identify patterns, make decisions with minimal human intervention, and predict outcomes based on historical data.
See More...See Less..., 'trainingThe process of teaching an artificial intelligence (AI) system to make decisions or predictions based on data. This involves feeding large amounts of data into the AI algorithm, allowing it to learn and adapt. The training can involve various techniques like supervised learning, where the AI is given input-output pairs, or unsupervised learning, where the AI identifies patterns and relationships in the data on its own. The effectiveness of AI training is critical to the performance and accuracy of the AI system.
See More...See Less...' a neural network is akin to coaching a new employee through the intricacies of sorting coins. As we'd seen earlier in our discussion, training can be approached via supervised learningSupervised Learning is a type of machine learning where models are trained on labeled data to make predictions or decisions.
See More...See Less... or unsupervised learningA type of machine learning where the algorithm learns patterns from data without being given explicit instructions or labels. It identifies commonalities in the data and responds based on the presence of these patterns.
See More...See Less.... To grasp these concepts, it's crucial to understand 'labelsIn the context of AI, labeling is the process of identifying and marking data with labels to indicate the output or category that the data belongs to. This is crucial in supervised learning for training models to recognize patterns or make predictions.
See More...See Less....' Imagine each coin has a tag specifying its year of minting—that tag is a 'label.' It gives clear information about the coin, which can be used to guide the sorting process.
Now, let's explore how our coin analogy applies to these two foundational types of neural network training:
Aspect
Supervised Learning
Unsupervised Learning
DataData, in everyday terms, refers to pieces of information stored in computers or digital systems. Think of it like entries in a digital filing system or documents saved on a computer. This includes everything from the details you enter on a website form, to the photos you take with your phone. These pieces of information are organized and stored as records in databases or as files in a storage system, allowing them to be easily accessed, managed, and used when needed.
See More...See Less... Type
Labeled Data
Unlabeled Data
Learning
The algorithm learns from the provided labels.
The algorithm infers patterns from the data.
Feedback
Direct Feedback (Corrective)
Indirect Feedback (No explicit correction)
Success Metric
Accuracy of sorting based on labels.
Quality of the discovered groupings or patterns.
In supervised learning, the 'training' involves a set of data that's already labeled—like our coins with year tags. This method is akin to giving the employee a reference guide to sort coins into pre-defined categories. They receive direct feedback—such as being corrected when a coin is placed in the wrong year—and their performance is measured by how accurately they can apply these learnings to new coins.
Conversely, unsupervised learning deals with unlabeled data, akin to a pile of coins without year tags. The employee—or algorithm in this case—learns to discern and create categories based on patterns they observe, such as color, size, and weight, sometimes employing clusteringA type of machine learning where the algorithm learns patterns from data without being given explicit instructions or labels. It identifies commonalities in the data and responds based on the presence of these patterns.
See More...See Less... algorithms like K-meansA method in data analysis for grouping data points into a user-defined number of clusters, denoted as a variable 'K'. Clusters are formed by grouping data points that share similarities in their features. Once data is arranged in clusters, the algorithm calculates the center, or centroid, of each cluster. The distance between each data point and the centroid of its cluster is calculated. The centroids are recalculated as the average position of all the data points in each cluster, and this process repeats until the clusters are stable. This method aims to create clusters with high similarity within each group and distinct differences between different groups.
See More...See Less... or using dimensionality reductionA technique in data processing where the number of variables or features in a dataset is reduced. The aim is to simplify the dataset while retaining its essential characteristics, making it easier to analyze or visualize. Reducing dimensionality can help in enhancing computational efficiency, reducing storage space, and potentially improving the performance of machine learning models by eliminating irrelevant or redundant data features. This process can involve either selecting the most relevant features (feature selection) or transforming features into a new set of principal variables (feature extraction).
See More...See Less... techniques like PCADimensionality in data refers to the number of attributes or features that represent a dataset. Dimensionality reduction techniques like PCA are used to reduce the number of features in a dataset by transforming the data into a new set of variables that retain most of the original data's variability.
See More...See Less... to uncover these patterns. They adjust their sorting criteria based on the inherent structure of the coins, without knowing if there's a 'right' or 'wrong' way to sort them. The success isn't about matching a label but about how effectively the algorithm can group coins and apply this to new sets. AutoencodersAn autoencoder is a type of neural network that simplifies complex data. It works by compressing the data, reducing it to its most essential features and eliminating less important details. This makes the data easier to work with and understand. The neural network then uses this simplified version of the data to identify key patterns and differences. This process is particularly useful for reducing the complexity of data (dimensionality reduction), learning important characteristics of the data (feature learning), and creating new data based on these patterns (generative models). The goal is to make the underlying structure of the data more manageable and useful for analysis and decision-making.
See More...See Less... (covered later) could also be employed for unsupervised learning, where success would be to shorten the description of each coin without losing any important information that helps identify it.
Understanding these two approaches helps businesses decide how to implement machine-learning solutions. Whether sorting coins or sorting through complex data, the choice between supervised and unsupervised learning hinges on the nature of the data at hand and the specific goals of the task.
Balancing Knowledge and Flexibility in Training
When you're teaching an employee to sort coins by year, the goal is for them to grasp the broad featuresIn artificial intelligence, a feature is an individual measurable property or characteristic of a phenomenon being observed. Choosing informative, discriminating, and independent features is a crucial step for effective algorithms in pattern recognition, classification, and regression.
See More...See Less... that characterize coins from different eras, rather than memorizing the specific details of each coin in front of them. It's akin to guiding a student to understand the principles behind the lessons instead of memorizing the textbook. Just as an overzealous student might memorize facts without grasping the underlying concepts, but struggle to adapt this knowledge to new problems, an employee might focus too narrowly on the coins they've already handled. To prevent this sort of "overfittingThis occurs in machine learning when a model learns the training data too well, including its noise and outliers. As a result, it performs poorly on new, unseen data because it has essentially memorized the training data rather than learning to generalize.
See More...See Less..." in training, we introduce a variety of coins from different piles or sets throughout the process, while also ensuring that the modelA model in machine learning is a mathematical representation of a real-world process learned from the data. It's the output generated when you train an algorithm, and it's used for making predictions.
See More...See Less... is not too simplistic to capture the underlying trend in the data, which could lead to “underfittingA modeling error in machine learning which occurs when a data model is too simple to capture the underlying pattern in the data. This often leads to poor predictive performance, as the model fails to generalize well from the training data to unseen data.
See More...See Less....”
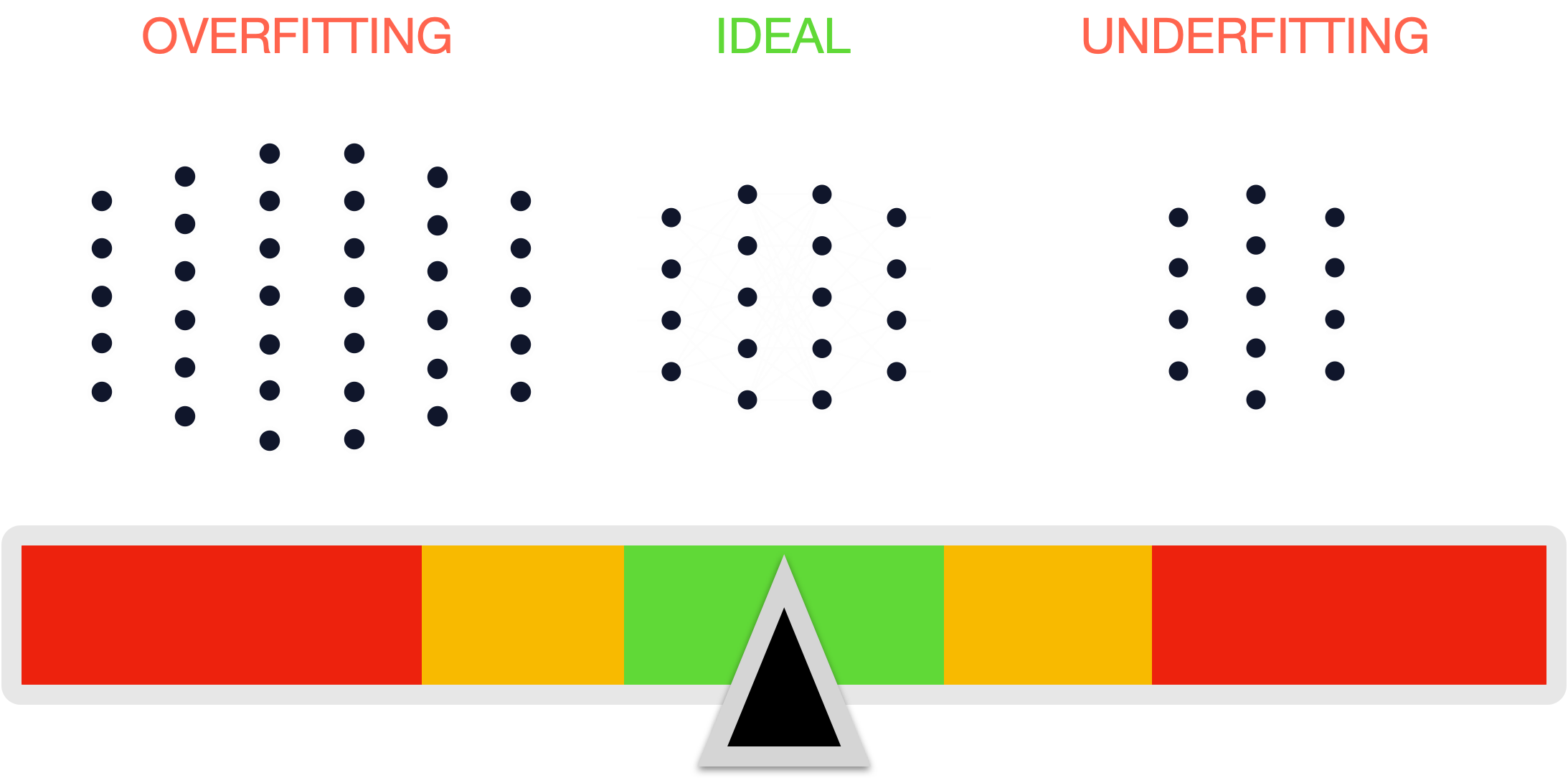
The image below illustrates the concepts of “overfitting” and “underfitting”. Between these two extremes is a graphic showing the ideal model complexity in machine learning. On the left, the model labeled "Overfitting" has an excessive number of connections and layers, representing a highly complex network that may perform exceptionally on training data but poorly on unseen data due to capturing noise rather than the underlying pattern. On the right, the "Underfitting" model has sparse connections and layers, suggesting a model that is too simple to capture the complexity of the data, resulting in poor performance on both training and new data. The middle model, marked "Ideal," shows a balanced structure with an optimal number of layers and connections, indicating a well-tuned model that can apply accumulated learning well to new data. This visual metaphor helps convey the importance of model complexity in machine learning and the trade-off between a model's ability to learn from data and its capacity to generalize from that learning.
Cross-Validation Explained Through Coin Sorting
In cross-validationCross-validation is a statistical method used to estimate the skill of machine learning models. It is commonly used to validate a model's performance on an independent dataset in a robust way.
See More...See Less..., we don't just show the neural network one set of data during training. Instead, we divide our data into several parts, or 'foldsFolds are equally divided sections of a dataset used in training and validating a model multiple times. This helps in assessing how well the model performs with different parts of the data.
See More...See Less...'. The neural network trains on some of these folds and then validates what it has learned on a different fold, a bit like a pop quiz. We rotate which fold is used for validation, ensuring each part of the data is used for testing the model, mimicking k-fold cross-validationK-fold is a cross-validation method where a dataset is divided into k number of folds where each fold is used as a testing set at some point. This allows for a more robust model validation process.
See More...See Less... in practice.
Returning to our coin analogy, it would be like having several bags of coins and asking the employee to sort one bag at a time while using coins from the other bags to test their sorting rules. This way, you make sure they can't just memorize the coins in front of them; they need to learn the general sorting principles that can apply to any bag of coins they might encounter.
The Role of Cross-Validation in Avoiding Overfitting
By using cross-validation, you help ensure the employee doesn't overfit to one specific set of coins. They develop a robust understanding of how to sort any coin by year, not just the ones they've seen. In machine learning, cross-validation helps us catch overfitting early by showing us how well the model performs on different subsets of the data—giving us confidence that it's truly learning the patterns rather than memorizing the noise.
This balanced training, with the help of cross-validation, is crucial for creating a model—or training an employee—that performs well in the real world, ready for the variety and unpredictability of new coins or data it will encounter.
How AI Learns to Improve: The Importance of Feedback in Machine Learning
The loss functionA loss function is a method of evaluating how well specific algorithm models the given data. If predictions deviate from actual results, loss functions provide a measure of the error.
See More...See Less... in a neural network is analogous to a performance review that guides an employee's improvement. It's a measure of how well the network is doing its job. If our employee incorrectly sorts a 1995 coin into the 1996 pile, the loss function is akin to the supervisor pointing out the mistake and suggesting a closer look at the coin's features.
In technical terms, the loss function calculates the difference between the neural network's predictions and the actual target values. It's the cornerstone of learning, as it provides a quantitativeQuantitative refers to a type of data that can be counted or measured, and expressed numerically, allowing for statistical analysis to identify patterns, trends, and predictions.
See More...See Less... basis for the network to adjust its weights, which means improving its sorting strategy. A good loss function will guide the network towards making fewer mistakes over time, just as constructive feedback helps our employee become more adept at sorting coins.
Wise use of a loss function ensures that our digital 'employee' doesn't just memorize the data (the result of “overfitting”) but learns to apply its rules to sort through any new coins — or data — it encounters. This is critical for successfully training neural networks.
Through iterations of this process, bolstered by feedback mechanisms like backpropagationBackpropagation is a method used in artificial neural networks to calculate the error contribution of each neuron after a batch of data is processed. It is a key algorithm used to train feedforward neural networks.
See More...See Less... and optimization algorithms, the neural network fine-tunes its parameters. This is how it evolves from a naïve state, with random guesses, to a trained state that makes informed predictions and decisions, much like our employee grows from a novice sorter to an expert coin classifier.
The Need for Computational Power in Training: The Role of GPUs
Training an AIA branch of computer science that focuses on creating systems capable of performing tasks that typically require human intelligence. These tasks include learning, reasoning, problem-solving, perception, and language understanding. AI can be categorized into narrow or weak AI, which is designed for specific tasks, and general or strong AI, which has the capability of performing any intellectual task that a human being can.
See More...See Less... model is a resource-intensive task that involves processing vast amounts of data and performing complex mathematical operations millions or even billions of times. This is where GPUsA specialized electronic circuit designed to accelerate the processing of images and videos for output to a display. While originally designed for graphics, GPUs are now also used in a variety of computational tasks due to their parallel processing capabilities.
See More...See Less... (Graphics Processing UnitsA specialized electronic circuit designed to accelerate the processing of images and videos for output to a display. While originally designed for graphics, GPUs are now also used in a variety of computational tasks due to their parallel processing capabilities.
See More...See Less...) come into play. Originally designed for rendering graphics, GPUs are incredibly efficient at matrix and vector computations, which are fundamental to the operations in neural network training. Their architecture allows them to execute many parallel operations simultaneously, significantly accelerating the training process.
Parallel Processing Power
Unlike CPUsThe primary component of a computer that performs most of the processing. It interprets and carries out instructions, manages inputs and outputs, and communicates with all other hardware devices in the system.
See More...See Less..., which are optimized for sequential task processing and handling a broad range of computations, GPUs are composed of thousands of smaller, more efficient coresA core in a processor is an individual processing unit within a computer's CPU (Central Processing Unit). Multiple cores can handle different tasks simultaneously, improving overall computer performance.
See More...See Less... designed for parallel processingA method of performing multiple computations or processes simultaneously. This can be achieved using multiple processors in a computer system or by a single processor handling multiple tasks concurrently, often through time-slicing or multi-threading. Parallel processing is used to increase efficiency and speed in various computing tasks.
See More...See Less.... When training a neural network, a GPUA specialized electronic circuit designed to accelerate the processing of images and videos for output to a display. While originally designed for graphics, GPUs are now also used in a variety of computational tasks due to their parallel processing capabilities.
See More...See Less... can update thousands of weights at once, making it vastly faster than a CPUThe primary component of a computer that performs most of the processing. It interprets and carries out instructions, manages inputs and outputs, and communicates with all other hardware devices in the system.
See More...See Less... for this kind of task.
The Computational Heaviness of Training
During training, neural networks go through a process of backpropagation, where errors are calculated and propagated back through the networkA collection of interconnected computers, servers, and other devices that allow for the exchange and sharing of data and resources. Networks can be classified based on size, function, and access. Common types include Local Area Network (LAN), which connects devices in a localized area such as an office or home; Wide Area Network (WAN), which connects devices across large distances, possibly globally; and Virtual Private Network (VPN), which provides secure, encrypted connections over the internet. A network relies on standardized protocols, such as TCP/IP, to ensure uniform communication and data transfer between devices.
See More...See Less... to adjust the weights. This process requires a considerable amount of computation and memoryRefers to the components or devices where data is stored for immediate use in a computer or related computing device. Memory typically refers to Random Access Memory (RAM), which is the main memory used by a computer to store data temporarily while it is being processed or accessed by the CPU. This memory is volatile, meaning it loses its content when the computer is turned off.
See More...See Less... bandwidthThe capacity for transmitting data over a network connection or circuit, measured in bits per second. It indicates the maximum rate at which data can be sent, impacting the speed and efficiency of data transmission.
See More...See Less.... GPUs excel in this area due to their high number of cores and specialized design, which allows them to handle multiple calculations at lightning speeds. Additionally, tasks like gradient descent optimizationA technique in machine learning, where the computer improves its predictions or decisions by making small, iterative adjustments. It's like trying to find the lowest point in a valley blindfolded. The computer starts with a guess and then, based on feedback – like a hiker feeling the slope of the ground – makes small changes to get closer to the best answer. Each change is guided by the gradient, or the slope of the error landscape, and the computer's goal is to descend to the lowest point of this landscape. This lowest point represents the most accurate predictions the model can make. The process gradually helps the computer learn from data in a more effective and accurate way.
See More...See Less... and the tuning of hyperparametersSettings or configurations that are set before starting the training process of a machine learning model. They are not learned from the data but chosen by the person creating the model, and they can greatly affect the model's performance. Examples include learning rate and number of trees in a random forest.
See More...See Less... are computationally expensive operations that benefit from the raw power of GPUs.
Why GPUs Aren't as Necessary for Inference
Once a model is trained, the heavy lifting has been done. The model no longer needs to learn; it simply applies what it has learned to make predictions. This task, while still computationally demanding, is less intense and can be handled efficiently by CPUs, which are more common in everyday devices. During inferenceInference is the stage where a previously trained machine learning model is used to analyze new data. Unlike the training phase, where the model learns patterns from a known dataset, inference involves applying the learned patterns to make predictions or decisions on new, unseen data. The model does not learn or change during this phase; it only uses its existing knowledge to interpret and process the new data.
See More...See Less..., the neural network performs a straightforward series of matrix multiplicationsA mathematical operation where two matrices (arrays of numbers arranged in rows and columns) are combined to produce a new matrix. This process involves multiplying the rows of the first matrix with the columns of the second matrix and summing the results to form the elements of the new matrix. Matrix multiplication is a fundamental operation in many areas, including computer graphics, physics, and machine learning.
See More...See Less... as data passes through the trained network, a task well within the capabilities of modern CPUs, especially when optimized for these operations.
Once a model is trained, the heavy lifting has been done. The model no longer needs to learn; it simply applies what it has learned to make predictions. This task, while still computationally demanding, is less intense and within the capabilities of modern CPUs (although, depending on the model, a GPU may still be necessary for performance). During inference, the neural network performs a straightforward series of matrix multiplications as data passes through the trained network, a task well within the capabilities of modern CPUs, especially when optimized for these operations.
Energy Efficiency in Inference and the Role of Edge Devices
Energy efficiency becomes paramount when we talk about edge devices. But what exactly is an edge device? An edge device is a piece of hardware that processes data closer to the source of data generation (like a camera or a smartphone) rather than relying on a centralized data-processing warehouse. These devices typically have constraints on power, size, and processingIn computing, a process is an instance of a computer program that is being executed. It contains the program code and its current activity. Each process has a unique process ID and maintains its own set of resources such as memory and processor state. A process can initiate sub-processes, creating a tree of processes.
See More...See Less... capacity. CPUs in these devices are engineered to provide the necessary computational power for real-time AI applications such as voice recognition or image processingThe technique of reading, manipulating, or altering digital images using a computer. It involves applying various methods and algorithms to enhance, analyze, or change the appearance of an image. Image processing is used in fields such as photography, medical imaging, and computer graphics.
See More...See Less..., while also conserving energy to maintain battery life and device longevity. Complementing these advancements, specialized chips for running neural networks exist and are becoming increasingly common on the edge, further enhancing their capabilities.
Division of Labor
In the realm of AI, GPUs play a crucial role in training models by leveraging their parallel processing capabilities to handle the computationally intense tasks of learning and optimization. Once the model is trained, however, the baton is passed to CPUs, especially in edge devices, for efficient and energy-conservative inference. This division of labor between GPUs for training and CPUs for inference is what enables AI to be both powerful in development and practical in deployment.