
In our quest to explain the vast and intricate world of artificial intelligence (AI), we continue our 'AI Demystified Series' with a dive into a concept that is less discussed outside expert circles but is revolutionary in the way we approach data: autoencoders.
These neural networks stand at the forefront of unsupervised learning, but their function and utility can sometimes be overshadowed by their more complex nature. Today, we aim to demystify autoencoders, illustrating how they simplify and refine our data, serving as a foundational element in the architecture of AI.
Autoencoders are a class of neural networks with a somewhat counterintuitive task: they are designed to replicate their input data to their output. This replication, however, isn't the main objective. The true 'magic' of autoencoders unfolds in the process of data compression, where the network distills the input into a lower-dimensional, compact representation — much like boiling down a sprawling article into a handful of key bullet points. This ability to abstract the essence of the data is realized through a two-part process: encoding and decoding.
During the encoding phase, the network transforms the input into a condensed, more efficient representation. Imagine it as a way of distilling the core message or features from a broad set of information. Then, in the decoding phase, the network performs what might seem like a conjuring trick: it reconstructs the input data from this compact version, albeit imperfectly. The success of the reconstruction phase is indicative of the autoencoder having captured the most significant attributes of the data.
At first glance, it might seem odd to train a network for what appears to be a redundant task — outputting what it takes in. But the brilliance lies not in the replication itself, but in the network's ability to discern and prioritize the input data's most salient features for the final output. This selective encoding is where autoencoders reveal their true value.
Consider the task of packing a suitcase for an extended vacation. Your objective is to bring along everything necessary for your experience without your suitcase becoming cumbersome. This parallels the essence of autoencoders in data processing.
In the encoding phase, akin to selecting which items to pack, you're forced to prioritize. You can't take everything, so you choose the essentials—the most functional and versatile items for your trip. These selections represent a "compressed" collection of your belongings, emphasizing utility over quantity.

Upon arrival and during the decoding phase—unpacking—you'll discover whether your choices were sufficient to replicate the comfort and functionality you enjoy at home. Well-chosen contents that fulfill your needs confirm that your compact suitcase captured the essentials, just as a well-trained autoencoder retains critical data while discarding the unnecessary items.
Autoencoders, thus, neatly "pack" data into a reduced form, preserving essential information before "unpacking" it to reconstruct the initial dataset. A successful reconstruction shows the network's ability to identify and maintain the valuable aspects of data, akin to smartly packing your preferred and most useful items.
Autoencoders have emerged as a pivotal technology in healthcare, transforming the way medical data is analyzed and utilized. These powerful neural networks have the capability to sift through immense volumes of patient data, extracting the essence of the information while discarding redundancy and noise. This attribute is particularly beneficial in identifying hidden patterns indicative of disease states, which might be too subtle for traditional analysis or human detection.
For instance, in medical imaging, autoencoders can be trained on thousands of radiographic images to learn representations that capture underlying pathologies such as tumors or fractures, significantly expediting the diagnostic process.
In genetics, autoencoders assist in the interpretation of complex genetic data. They can reveal patterns associated with genetic disorders, even when the relationship between genetic markers and the disease is not fully understood. By encoding the vast genetic information into a more manageable form, researchers can more easily spot mutations and variants that correlate with specific conditions, advancing the understanding and potential treatment of genetic diseases.
By distilling patient information into actionable knowledge, autoencoders enable personalized care, enhancing treatment effectiveness and efficiency in the healthcare sector.
Autoencoders excel in behavioral analysis, learning what typical user or system activity looks like within a network. This learning enables them to monitor network traffic in real-time, comparing ongoing activity to established 'normal' patterns. Any deviation is flagged as an anomaly, potentially revealing cybersecurity threats such as unauthorized access, malware infections, or insider risks. The strength of autoencoders in this domain lies in their ability to learn from unlabeled data—a significant advantage given the impracticality of labeling in the dynamic and complex landscape of cyber threats. Their adaptability ensures that as they encounter new data, they evolve, becoming more adept at detecting novel threats. Thus, autoencoders have become indispensable in sustaining cybersecurity in the face of sophisticated attacks and vulnerabilities.
Autoencoders are prized for their ability to distill data into more manageable forms, making them indispensable for intricate analyses and noise reduction tasks. Yet, their very efficiency in data compression can obscure the understanding of the underlying processes. The complex, encoded representations they generate are powerful but can be opaque, making them less suitable in scenarios where clear interpretability is essential, such as in regulatory compliance or medical diagnostics where stakeholders must understand the AI's decision-making process.
Autoencoders excel in transforming complex datasets into streamlined, essential representations, making them highly effective for detailed analyses and denoising tasks. Their proficiency in data compression is particularly advantageous when working with large-scale or high-dimensional data where discerning the significant features from the noise is akin to finding a needle in a haystack.
However, the compact and intricate encodings they produce, while computationally efficient, can veil the inner workings of the model. In fields such as finance, healthcare, and legal compliance, where decisions need to be transparent and explainable, the "black box" nature of deep autoencoders can pose a significant barrier. Deciphering the reasons behind an autoencoder's output is often not straightforward, leading to challenges in validation and trust by end-users.
Moreover, in applications like precision medicine, where treatment decisions could hinge on algorithmic recommendations, the stakes for interpretability are exceptionally high. Here, practitioners not only require confidence in the model's predictive power but also need to understand the basis of its conclusions to integrate them into holistic patient care.
Recognizing these challenges, researchers are continually developing techniques to peel back the layers of autoencoder decision-making. Methods such as feature visualization, model distillation, and attention mechanisms are among the frontiers being explored to bridge the gap between autoencoder utility and user interpretability. These innovations aim to not only retain the models' powerful data-simplifying capabilities but also illuminate their decision pathways, fostering trust and broadening their applicability in sensitive and critical domains.
Thus, the journey of autoencoders, from being mere data-compressing workhorses to becoming transparent, explainable models, is an evolving narrative in the field of AI, reflecting a delicate balance between performance and clarity that defines modern machine learning.
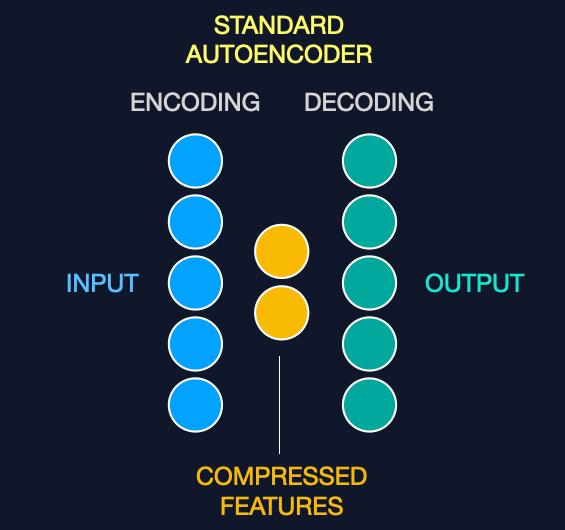
While we've explored how autoencoders can compress and reconstruct data, it's worth distinguishing between the common types: standard and deep autoencoders.
Standard Autoencoders have a single hidden layer to encode and decode information, which is sufficient for learning simple data representations. They work like a basic compression tool, summarizing and then restoring data with minimal layers.
Deep Autoencoders, on the other hand, employ multiple hidden layers, offering a more nuanced data understanding. Think of them as advanced compression tools with extra settings that capture intricate details, which is ideal for complex data like high-resolution images.
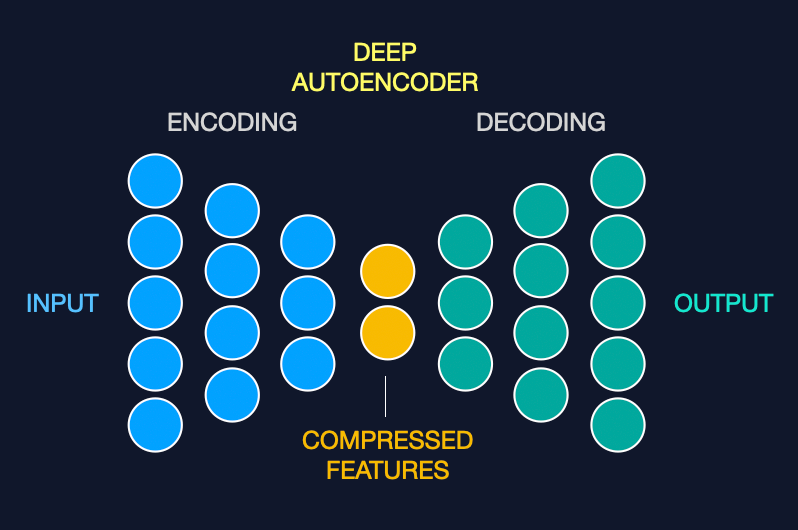
Adding layers to an autoencoder allows it to learn hierarchical features, with each layer capturing increasingly abstract representations of the data. This depth can lead to more accurate reconstructions for complex datasets, akin to restoring an image with fine details rather than just broad strokes.
However, deep autoencoders require careful training to prevent overfitting and to ensure that each layer effectively captures relevant information. Despite these challenges, their ability to unearth subtle patterns makes them valuable for advanced tasks in AI, complementing the foundational techniques of standard autoencoders.
Autoencoders are a significant achievement in the realm of neural network technology, cleverly balancing the act of compression and reconstruction to extract the essence of vast datasets. Their true strength, however, is not just in their standalone capabilities but in their symbiotic relationship with other machine-learning techniques. By combining autoencoders with various algorithms, we can enhance predictive models, refine anomaly detection, and unlock deeper insights across countless applications.
As the field of AI continues to evolve, autoencoders will undoubtedly remain a cornerstone, not only for their data distillation abilities but also for their integral role in a comprehensive machine learning toolkit that pushes the boundaries of innovation and efficiency.













